 Photo by Clément H
Photo by Clément HOriginally Posted On: https://ironsoftware.com/csharp/ocr/tutorials/how-to-read-text-from-an-image-in-csharp-net/
How to read text from images with C# OCR
In this tutorial, we will learn how to convert images to text in C# and other .NET languages. We will use the Iron OCR library to recognize text within images and look at the nuances of how to use Iron OCR to get the highest performance in terms of accuracy and speed when reading text from images in .NET Hello World.
To achive Image to Text we will install the IronOCR OCR library into a Visual Studio project.
To do this, we Download the IronOcr DLL or use Nuget.
PM > Install-Package IronOcr
AutoOCR
In this simple example, you can see we use the IronOcr.AutoOcr class to read the text from an image and automatically return its value as a string.
- using IronOcr;
- AutoOcr OCR = new AutoOcr() { ReadBarCodes = false };
- var Results = OCR.Read(“img/Screenshot.png”);
- Console.WriteLine(Results.Text);
Copy code to clipboardVB C#
Although this may seem simplistic, there is sophisticated behavior going on ‘under the surface’: scanning the image for alignment, quality and resolution, looking at its properties, optimizing the OCR engine, and using a trained artificial intelligence network to then read the text as a human would.
OCR is not a simple process for a computer to achieve, and reading speeds may be similar to those of a human. In other words, OCR is not an instantaneous process. In this case though, it is 100% accurate.
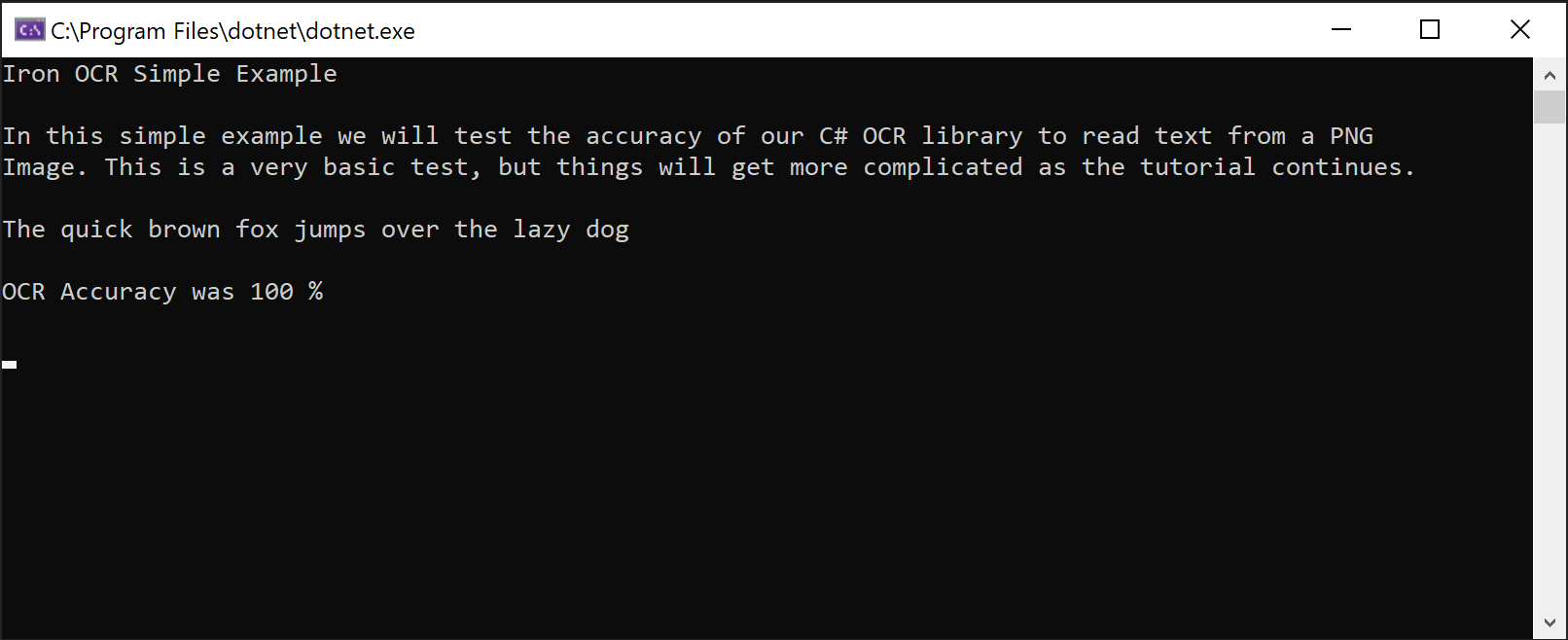
In most real world use cases, developers are going to want the best performance possible for their project. In this case, we recommend that you move forward from the Auto OCR example and look at the AdvancedOCR class within the Iron OCR namespace.
This gives you the facility to set the specific characteristics of an OCR job, such as:
- cleaning background noise;
- enhancing contrast;
- enhancing resolution;
- choosing a specific language;
- choosing particular OCR strategies (balance speed against performance);
- specifying color spaces;
- working with negative images where there is dark text on white backgrounds;
- specifying a document type whether we are looking at a screenshot, a snippet, or an entire document;
- specifying whether or not we wish to spend time correcting for skew, rotation, and perspective within the original scanned image;
- specifying if IronOCR read barcodes when we are performing OCR;
- and choosing the number of bits per pixel within our color depth.
This all may seem daunting, but in the example below you will see the default settings which we would recommend you start with, which will work with almost any image you input to Iron OCR.
- var Ocr = new AdvancedOcr()
- {
- CleanBackgroundNoise = true,
- EnhanceContrast = true,
- EnhanceResolution = true,
- Language = IronOcr.Languages.English.OcrLanguagePack,
- Strategy = IronOcr.AdvancedOcr.OcrStrategy.Advanced,
- ColorSpace = AdvancedOcr.OcrColorSpace.Color,
- DetectWhiteTextOnDarkBackgrounds = true,
- InputImageType = AdvancedOcr.InputTypes.Document,
- RotateAndStraighten = true,
- ReadBarCodes = true,
- ColorDepth = 4
- };
- var Results = Ocr.Read(“any_image_or_pdf.pdf”);
Copy code to clipboardVB C#
Example: A Medium Quality Scan

In the following example we will perform OCR on a medium quality TIFF scan of a page from Harry Potter and the Chamber of Secrets.
- var Ocr = new AdvancedOcr()
- {
- CleanBackgroundNoise = false,
- EnhanceContrast = true,
- EnhanceResolution = false,
- Language = IronOcr.Languages.English.OcrLanguagePack,
- Strategy = IronOcr.AdvancedOcr.OcrStrategy.Advanced,
- ColorSpace = AdvancedOcr.OcrColorSpace.Color,
- DetectWhiteTextOnDarkBackgrounds = false,
- InputImageType = AdvancedOcr.InputTypes.Document,
- RotateAndStraighten = false,
- ReadBarCodes = false,
- ColorDepth = 4
- };
- var Results = Ocr.Read(“img/Potter.tiff”);
Copy code to clipboardVB C#
As you can see, reading the text (and optionally barcodes) from a scanned image such as a TIFF was rather easy. This OCR job yields an accuracy of 96.5%. OCR is not a perfect science when it comes to real world documents.
You will also note that Iron OCR can automatically read multipage documents, such as TIFFs and even PDF documents, automatically with these settings.
Example: A Low Quality Scan

Now we will try a much lower quality scan of the same page, at a low DPI, which has lots of distortion and digital noise and damage to the original paper.
This is where IronOCR truly shines against other OCR libraries such as Tesseract, and we will find alternative OCR projects shy away from discussing. OCR on real world scanned images rather than unrealistically ‘perfect’ test cases created digitally to give a 100% OCR accuracy.
- var Ocr = new AdvancedOcr()
- {
- CleanBackgroundNoise = true,
- EnhanceContrast = true,
- EnhanceResolution = true,
- Language = IronOcr.Languages.English.OcrLanguagePack,
- Strategy = IronOcr.AdvancedOcr.OcrStrategy.Advanced,
- ColorSpace = AdvancedOcr.OcrColorSpace.GrayScale,
- DetectWhiteTextOnDarkBackgrounds = false,
- InputImageType = AdvancedOcr.InputTypes.Document,
- RotateAndStraighten = true,
- ReadBarCodes = false,
- ColorDepth = 4
- };
- var Results = Ocr.Read(“img/Potter.LowQuality.tiff”);
Copy code to clipboardVB C#
This OCR job yields an accuracy of 95.6% which is almost as accurate as the OCR of a high quality scan, although it may take a little longer to run.
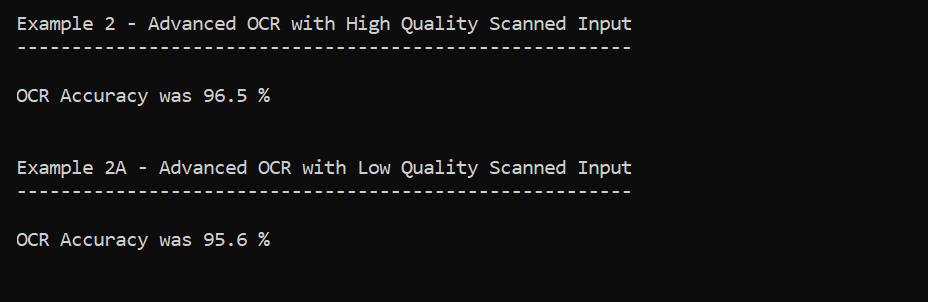
The most important factor in the speed of an OCR job is in fact the quality of the input image. The less background noise that is present and the higher the dpi, with a perfect target dpi at about 300 dpi, will cause the fastest and most accurate OCR results.
This is not, however, necessary, as Iron OCR shines at correcting imperfect documents (though this is time-consuming and will cause your OCR jobs to use more CPU cycles).
If possible, choosing input image formats with less digital noise such as TIFF or PNG can also yield faster results than lossy image formats such as JPEG.
Example: Setup for SpeedUsing AdvancedOCR, we may wish to disable some of the more time-consuming features, such as clean background noise, enhance contrast, enhance resolution, rotate & straighten, if we do not believe that these features are necessary for our specific input documents. This will save up to 50% of the OCR time.
If optimizing for speed we might start at this position and then turn features back on until the prefect balance is found.
- var Ocr = new AdvancedOcr()
- {
- CleanBackgroundNoise = false,
- EnhanceContrast = false,
- EnhanceResolution = false,
- Language = IronOcr.Languages.English.OcrLanguagePack,
- Strategy = IronOcr.AdvancedOcr.OcrStrategy.Fast,
- ColorSpace = AdvancedOcr.OcrColorSpace.GrayScale,
- DetectWhiteTextOnDarkBackgrounds = false,
- InputImageType = AdvancedOcr.InputTypes.Document,
- RotateAndStraighten = false,
- ReadBarCodes = false,
- ColorDepth = 4
- };
- var Results = Ocr.Read(“img/300dpi.png”);
Copy code to clipboardVB C#
Reading Cropped Regions of ImagesAs you can see from the following code sample, Iron OCR is adept at reading specific areas of images. We may use a System.Drawing.Rectangle to specify, in pixels, the exact area of an image to read.
This can be incredibly useful when we are dealing with a standardized form which is filled out, where only a certain area has text which changes from case to case.
Example: Scanning an Area of a PageWe can use a System.Drawing.Rectangle to specify a region in which we will read a document. The unit of measurement is always pixels.
We will see that this provides speed improvements as well as avoiding reading unnecessary text. In this example we will read a students name from a central area of a standardized document.


- var Ocr = new IronOcr.AutoOcr();
- var Area = new System.Drawing.Rectangle() { X = 215, Y = 1250, Height = 280, Width = 1335 };
- var Results = Ocr.Read(“img/ComSci.Png”, Area);
- Console.WriteLine(Results.Text);
Copy code to clipboardVB C#
Cropping is also supported when reading PDFs – Click here to see the object reference.
International LanguagesIron OCR supports 22 international languages via language packs which are distributed as DLLs, which can be downloaded from this website, or also from the NuGet Package Manager for Visual Studio.
We can install them by browsing NuGet (search for “IronOcr Languages”) or from the OCR language packs page.
Supported languages Include:
- English
- Arabic
- ChineseSimplified
- ChineseTraditional
- Czech
- Danish
- Finnish
- French
- German
- Greek
- Hebrew
- Hungarian
- Italian
- Japanese
- Korean
- Norwegian
- Polish
- Portuguese
- Russian
- Spanish
- Swedish
- Thai
- Turkish
In the following example, we will show how we can scan an Arabic document.
PM> Install-Package IronOcr.Languages.Arabic
- var Ocr = new AutoOcr()
- {
- Language = IronOcr.Languages.Arabic.OcrLanguagePack,
- };
- var Results = Ocr.Read(“img/arabic.gif”);
- Console.WriteLine(“{0} Characters of Arabic Read”,Results.Text.Length);
- // Note that the .Net Console can not yet display Arabic characters… they all print as question marks.
Copy code to clipboardVB C#
Example: OCR in more than one languge in the same document.In the following example, we will show how to OCR scan multiple languages to the same document.
This is actually very common, where for example a Chinese document way contain English words and Urls.
PM> Install-Package IronOcr.Languages.ChineseSimplified
- var Ocr = new AdvancedOcr();
- Ocr.Language = new IronOcr.Languages.MultiLanguage(IronOcr.Languages.ChineseSimplified.OcrLanguagePack, IronOcr.Languages.English.OcrLanguagePack)
Copy code to clipboardVB C#
A Detailed Look at Image to Text OCR ResultsThe last thing we will look at in this tutorial is the OCR results object. When we read OCR, we normally only want the text out, but Iron OCR actually contains a huge amount of information which may be of use to advanced developers.
Within an OCR results object, we have a collection of pages which can be iterated. Within each page, we may find barcodes, power graphs, lines of text, words, and characters.
Each of these objects in fact contains: a location; an X coordinate; a Y coordinate; a width and a height; an image associated with it which can be inspected; a font name; the font size; the direction in which the text is written; the rotation of the text; and the statistical confidence that Iron OCR has for that specific word, line, or paragraph.
In short, this allows developers to create advanced OCR applications and to find out and deal with scenarios where they have less than 100% confidence in their input content.
- using IronOcr;
- using System;
- using System.Collections.Generic;
- using System.Drawing; //Add Assembly Reference
- // We can delve deep into OCR results as an object model of
- // Pages, Barcodes, Paragraphs, Lines, Words and Characters
- var Ocr = new AdvancedOcr()
- {
- Language = IronOcr.Languages.English.OcrLanguagePack,
- ColorSpace = AdvancedOcr.OcrColorSpace.GrayScale,
- EnhanceResolution = true,
- EnhanceContrast = true,
- CleanBackgroundNoise = true,
- ColorDepth = 4,
- RotateAndStraighten = false,
- DetectWhiteTextOnDarkBackgrounds = false,
- ReadBarCodes = true,
- Strategy = AdvancedOcr.OcrStrategy.Fast,
- InputImageType = AdvancedOcr.InputTypes.Document
- };
- var results = Ocr.Read(@”pathtodocument.png”);
- foreach (var page in results.Pages)
- {
- // page object
- int page_number = page.PageNumber;
- String page_text = page.Text;
- int page_wordcount = page.WordCount;
- List<OcrResult.OcrBarcode> barcodes = page.Barcodes;
- System.Drawing.Image page_image = page.Image;
- int page_width_px = page.Width;
- int page_height_px = page.Height;
- foreach (var paragraph in page.Paragraphs)
- {
- // pages -> paragraphs
- int paragraph_number = paragraph.ParagraphNumber;
- String paragraph_text = paragraph.Text;
- System.Drawing.Image paragraph_image = paragraph.Image;
- int paragraph_x_location = paragraph.X;
- int paragraph_y_location = paragraph.Y;
- int paragraph_width = paragraph.Width;
- int paragraph_height = paragraph.Height;
- double paragraph_ocr_accuracy = paragraph.Confidence;
- string paragraph_font_name = paragraph.FontName;
- double paragraph_font_size = paragraph.FontSize;
- OcrResult.TextFlow paragrapth_text_direction = paragraph.TextDirection;
- double paragrapth_rotation_degrees = paragraph.TextOrientation;
- foreach (var line in paragraph.Lines)
- {
- // pages -> paragraphs -> lines
- int line_number = line.LineNumber;
- String line_text = line.Text;
- System.Drawing.Image line_image = line.Image;
- int line_x_location = line.X;
- int line_y_location = line.Y;
- int line_width = line.Width;
- int line_height = line.Height;
- double line_ocr_accuracy = line.Confidence;
- double line_skew = line.BaselineAngle;
- double line_offset = line.BaselineOffset;
- foreach (var word in line.Words)
- {
- // pages -> paragraphs -> lines -> words
- int word_number = word.WordNumber;
- String word_text = word.Text;
- System.Drawing.Image word_image = word.Image;
- int word_x_location = word.X;
- int word_y_location = word.Y;
- int word_width = word.Width;
- int word_height = word.Height;
- double word_ocr_accuracy = word.Confidence;
- String word_font_name = word.FontName;
- double word_font_size = word.FontSize;
- bool word_is_bold = word.FontIsBold;
- bool word_is_fixed_width_font = word.FontIsFixedWidth;
- bool word_is_italic = word.FontIsItalic;
- bool word_is_serif_font = word.FontIsSerif;
- bool word_is_underlined = word.FontIsUnderlined;
- foreach (var character in word.Characters)
- {
- // pages -> paragraphs -> lines -> words -> characters
- int character_number = character.CharacterNumber;
- String character_text = character.Text;
- System.Drawing.Image character_image = character.Image;
- int character_x_location = character.X;
- int character_y_location = character.Y;
- int character_width = character.Width;
- int character_height = character.Height;
- double character_ocr_accuracy = character.Confidence;
- }
- }
- }
- }
- }
Copy code to clipboardVB C#
Putting this all together, we can see that if we input even an imperfect document [insert document] to Iron OCR, it can accurately read its content to a statistical accuracy of about 98% to 99%, even though the document was badly formatted, skewed, and had a lot of digital noise. This is unique to Iron OCR and is a feature you will not find in standard OCR libraries.
Moving ForwardTo continue to learn more about Iron OCR, we recommend you try the code samples on the IronOCR homepage, visit us on GitHub, or read the in-depth MSDN-style Object Reference.
Source Code DownloadYou may also enjoy the other .Net OCR tutorials in this section.
